![]()
Introducción
En este artículo se hace una introducción a los conceptos necesarios para el trabajo con sistemas de control de versiones. En particular, se orienta al aprendizaje de Mercurial, un sistema de control de versiones de última generación y carácter distribuido escrito por Matt Mackall.
El artículo forma parte de una serie que se publicará en este blog, y que se estructura de la siguiente manera:
- I – Conceptos generales
- II – Uso de Mercurial
- III – Publicación de proyectos
Sistemas de control de versiones (VCS)
Mercurial es un programa que permite mantener un registro histórico de los cambios realizados en el contenido de un proyecto. Normalmente se utiliza en proyectos de software, pero se puede utilizar para otros propósitos (elaboración de documentos, archivo de la configuración de un sistema, etc).
Estos programas son conocidos como sistemas de control de versiones (VCS, por sus siglas en inglés), o sistemas de gestión de código (SCM).
La gran ventaja de tener un registro de cambios es la posibilidad de recuperar versiones antiguas, visualizar los cambios hechos entre dos versiones, la seguridad de poder hacer pruebas sabiendo que se pueden deshacer los cambios, la capacidad de reconciliar cambios entre distintas «ramas» de un mismo proyecto, etc…
Sistemas de control de versiones centralizados y distribuidos (DVCS)
Tradicionalmente, y en los sistemas centralizados, el registro de cambios de un proyecto se almacenaba en un único servidor, que contenía toda la información de su historia, y del que dependían los distintos clientes para realizar operaciones que implicasen modificar o consultar la historia del proyecto. El gran problema de estos sistemas es que deja sin todos los beneficios del uso de un sistema de control de versiones a las personas que no tienen permiso de acceso (fundamentalmente de escritura) al servidor.
Una nueva generación de sistemas de control de versiones, conocidos como sistemas de control de versiones distribuidos, permiten que toda la información acerca de la historia de un proyecto no haya de mantenerse en un único archivo central. En estos sistemas cada copia del proyecto contiene esa información, lo que permite que cada persona que trabaja con una copia disponga de todas las ventajas del control de versiones, y se facilita la colaboración, puesto que es posible relacionar los cambios realizados en diferentes copias, localizando su ancestro común a partir del cual se producen divergencias en el código común.
Este nuevo modelo favorece una participación más equitativa en equipos distribuidos y una organización menos jerarquizada, sin impedir por ello la posibilidad de un funcionamiento similar al que exigen los sistemas centralizados.
Si bien puede parecer que el coste de mantener información redundante en cada copia de un proyecto puede ser excesivo, en la práctica rara vez lo es, gracias al uso de técnicas de compresión y la similitud entre versiones sucesivas. Aún en proyectos muy grandes, con amplias historias de cambios, como el kernel Linux o FreeBSD, el espacio ocupado en disco para almacenar la historia de cambios no alcanza apenas al espacio ocupado por los archivos versionados.
Un poco de vocabulario: repositorios, conjuntos de cambios (Changeset) y estado del directorio (dirstate)
Mercurial registra la historia de un proyecto almacenando una especie de «instantáneas» del mismo en lo que se denomina «repositorio» (almacén, depósito).
Esas «instantáneas», llamadas Changeset o conjuntos de cambios, contienen la versión en la que se encuentra cada uno de los archivos que se han «añadido» al repositorio, y son la pieza fundamental sobre la que se organiza Mercurial.
Así, el changeset 235 podría tener la versión 1 del archivo leeme.txt, la versión 5 del archivo COPYING, y no registra la existencia del archivo NEWS:
leeme.txt [versión 1]
COPYING [versión 5]
Por otra parte, el changeset 236 contiene el archivo leeme.txt en la misma versión (la 1), el archivo COPYING en la versión 6, y ya ha aparecido el archivo NEWS, en su versión 0:
leeme.txt [versión 1]
COPYING [versión 6]
NEWS [versión 0]
El conjunto de changesets de un proyecto podría ser algo así:
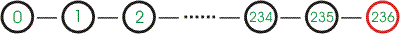
donde 0 es el changeset incial y (236) el último changeset registrado. Cada uno de esos estados del proyecto se registra indicando de forma explícita al sistema de control de versiones que se desean registrar los cambios. A esta operación se le conoce como hacer un envío de cambios o «commit«.
Algunos sistemas de control de versiones usan bases de datos para estructurar la información de los repositorios, pero, en Mercurial, un repositorio no es más que un directorio al que se añaden algunos metadatos. Estos metadatos los gestiona el sistema de forma transparente y automática, y están básicamente formados por los conjuntos de cambios del proyecto, además de por el estado actual del directorio de trabajo o «dirstate«.
El «dirstate» es el changeset padre, o el changeset del cual parte el contenido actual del directorio de trabajo. Este dato resulta necesario, puesto que el contenido del directorio de trabajo puede corresponder a cualquiera de las versiones registradas del proyecto o a una versión modificada de éstas… ya que el sistema permite navegar por la historia del proyecto.
En el esquema anterior, el dirstate sería el changeset 236, y contendría los siguientes archivos:
leeme.txt [versión 1]
COPYING [versión 6]
NEWS [versión 0]
Si modificamos esos contenidos, el changeset padre del directorio de trabajo seguiría siendo el 236, aunque los contenidos no serían iguales a dicha versión.
A la operación de recuperar en el directorio de trabajo una versión cualquiera de las registradas en el repositorio se le conoce como «actualizar» a una versión, y es una de las más útiles y habituales de las que permiten los sistemas de control de versiones.
En el ejemplo anterior, podríamos actualizar el directorio de trabajo a la versión 235:
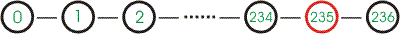
de manera que el dirstate corresponde al changeset 235, y el contenido del directorio de trabajo sería:
leeme.txt [versión 1]
COPYING [versión 5]
Ramas, cabezas de desarrollo, reconciliación de cambios y tip
Hasta ahora hemos visto la historia de un proyecto como un registro lineal, pero lo más habitual es que se produzcan divergencias en la historia del mismo, dando lugar a lo que se conocen como «ramas» de desarrollo («branches»).
Un ejemplo de aparición de divergencias es el siguiente:
- Se publica una nueva versión de un programa (v1.0 o changeset 212)
- Se siguen registrando nuevas funcionalidades en proceso de desarrollo (hasta el changeset 215)
- Surge un fallo inesperado en la versión publicada que exige la publicación de una nueva versión corregida
- Se actualiza el directorio de trabajo a la versión publicada (el dirstate cambia a 212)
- Se aplican las correcciones necesarias y se registra y publica la nueva versión (v1.1 o changeset 216)
- Se actualiza el directorio de trabajo para seguir trabajando en las nuevas funcionalidades (el dirstate cambia a 215)
- Se siguen añadiendo cambios (217)
- En este proceso acabamos con dos ramas: una versión incial más las nuevas funcionalidades (rama «en desarrollo«), una versión inicial con correcciones de fallos (rama «estable«).
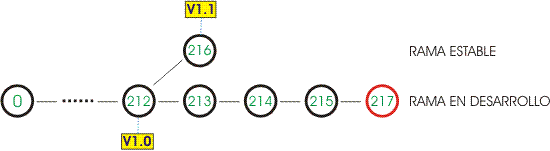
Al changeset más reciente de cada rama se le conoce como cabeza (head) de la rama. En nuestro ejemplo serían los changeset 216 y el 217. Al changeset más reciente del repositorio se le conoce como tip, y al final del proceso de nuestro ejemplo, sería el changeset 217.
En el ejemplo anterior, es imaginable que se desee integrar los cambios de la rama «estable» en la rama en «desarrollo«.
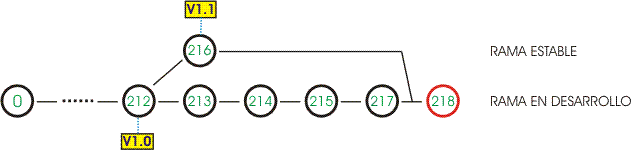
A este proceso se le denomina reconciliación de cambios, mezcla de ramas, o «merging«, y Mercurial realiza esta operación añadiendo un nuevo changeset (218) que unifica dos changeset padre (normalmente las cabezas, en este caso 216 y 217), e incluye en él las modificaciones necesarias para reconciliar los cambios entre ellas.
Números de revisión, changeset ID y etiquetas
Hemos visto que la mayor parte de las operaciones, como la actualización a una versión determinada, o la mezcla de ramas, es necesario referirse a los changeset del repositorio. Para ello, Mercurial permite utilizar tres sistemas distintos: el número de revisión, el changeset ID, o un tag (etiqueta).
El número de revisión es simplemente un número natural que corresponde al orden en el que se registró del changeset en el repositorio. Es la forma que hemos usado hasta ahora en los ejemplos, pero presenta el problema de que no identifica de forma única a un determinado changeset, sino que puede cambiar de máquina a máquina, en función de las diferencias en la historia de cada copia de un repositorio. Por ello no es útil más que para referirse a una copia concreta de un repositorio.
El changeset ID es un identificador único para un changeset, que lo identifica en un punto concreto de la historia de un repositorio, y es indepediente de la máquina en la que se sitúe. Permite referirse al mismo changeset en distintas copias de un repositorio. En Mercurial es un dato de 160bits, normalmente representado como una secuencia de 20 caracteres.
Una etiqueta (tag) es simplemente una cadena de texto que se liga a un changeset ID, y permite identificarlo de forma más conveniente. En nuestro ejemplo la etiqueta «v1.0» puede estar ligado al changeset ID: 58deccf0bead81a34691095db485a19efa1be709, que correspondía al número de revisión 212, mientras que el número de revisión 216 está marcado con la etiqueta «v1.1«. En los esquemas se señalan las etiquetas en cajas amarillas.
…y en el próximo capítulo…
La próxima parte de esta serie de artículos tratará sobre la instalación y el uso práctico de Mercurial.
NOTA: El logo de Mercurial se distribuye bajo licencia GPL, según las condiciones establecidas en el sitio web de Mercurial
Se permite la copia, distribución y modificación de este texto siempre que se conserve el copyright y esta nota.
Un comentario en “Control de Versiones con Mercurial (I) – Conceptos generales”